{kind=link}
It has been more than a decade since Google figured out that it needed to control its own hardware fate when it came to the tensor processing that was going to be required to support machine learning algorithms. A few weeks ago, at its annual I/O event, Google announced its sixth generation Tensor Processing Units, or TPUs, and there are still more questions than answers about them at this point.
This is fine, since we don’t expect Hypercomputer systems to be installed by Google using the TPU v6 devices until the fourth quarter of this year. But we are impatient observers of compute engine and system architecture, and have thus tried to figure out what the salient characteristics of these TPU v6 engines and how they might stack up in terms of bang for the buck compared to prior TPU generations. So, we have taken a first stab at a comparative analysis across the TPU line, which spans from the TPU v1, which was first deployed in 2015, and across eight distinct TPU devices including the new TPU v6.
The TPU engines and the systems that make use of them are not just a way to negotiate better pricing with Nvidia for GPU-style matrix math engines. The TPUs are also a way to drive fundamental research in mixed precision, matrix and serial processing design, memory subsystems, and interconnects for AI training and inference systems. This gives Google a baseline from which to compare systems based on Nvidia and AMD GPUs, on Intel Gaudi accelerators, and on specialized systems from the likes of SambaNova Systems, Cerebras Systems, Tenstorrent, and others.
The sixth generation of TPU, codenamed “Trillium,” are named after a species of plant colloquially known as wood lilies and existing in their most dense diversity in the Appalachian mountains of the southeastern United States. (This is where Google’s datacenter in Lenoir, North Carolina is located and also a half hour from where we live.) The TPU v6 is probably the first in what will very likely be a pair of devices, including one that has more oomph for inference workloads, which are very expensive to deploy at volume – even for rich companies like Google. The TPU v4i and TPU v5e devices were both tailored versions of the TPU v4 and TPUv5 architecture that were tuned to drive the bang for the buck for AI inference.
Details were pretty slim on the TPU v6 device, but we presume that eventually – meaning after the device goes into production on Google Cloud and is rentable by outside customers – the specs for the TPU v6 chip will be published in TPU system architecture documents that chronical from the TPU v2 through the TPU v5e currently.
What Google said in its blog post about the initial Trillium device is that the TPU v6 had 4.7X higher peak performance per chip compared to the TPU v5e, and also had twice the HBM memory capacity and twice the HBM memory bandwidth. The interchip interconnect (ICI) bandwidth linking TPU v6 chips together also had its bandwidth doubled. The Trillium devices also have the third generation of SparseCore accelerates for handling he embeddings that are commonly used in ranking and recommendation algorithms – the kind that drive Google’s search and advertising businesses and that are increasingly going to drive those of mainstream enterprises.
The Trillium chips have larger matrix multiply units (MXUs) than the ones used in the prior four generations, which use 128×128 matrices, but Google did not say how large. The TPU v1 chips used a 256×256 matrix in its cores, and we think Google may have reverted to this format and figured out a way to double pump it efficiently. (This certainly happened with vector engines inside of CPUs over the decades.) There is an outside chance that Google created a 192×192 matrix, but we doubt it. It violates our sense of symmetry.
Google added that the Trillium devices have 67 percent more energy efficiency than the TPU v5e chips, and can be podded up into blocks of 256 devices in a loosely coupled system for running AI workloads. As far as we know, the TPU v6 devices do not support 64-bit or 32-bit floating point math. The TPU v2 and TPU v3 chips supported the 16-bit BrainFloat (BF16) format for processing, while the TPU v1 just did INT8 integer format. With the TPU v4 and TPU v5 families of devices, both INT8 (commonly used for inference) and BF16 (commonly used for training) were supported with the MXUs. We are certain that the TPU v6 devices will support INT8 and BF16, but there is a chance that lower eight-bit and four-bit formats will also be supported with Trillium.
After mulling this over in our trusty spreadsheet, here is what we came up with as the possible feeds and speeds and pricing for the Trillium devices:
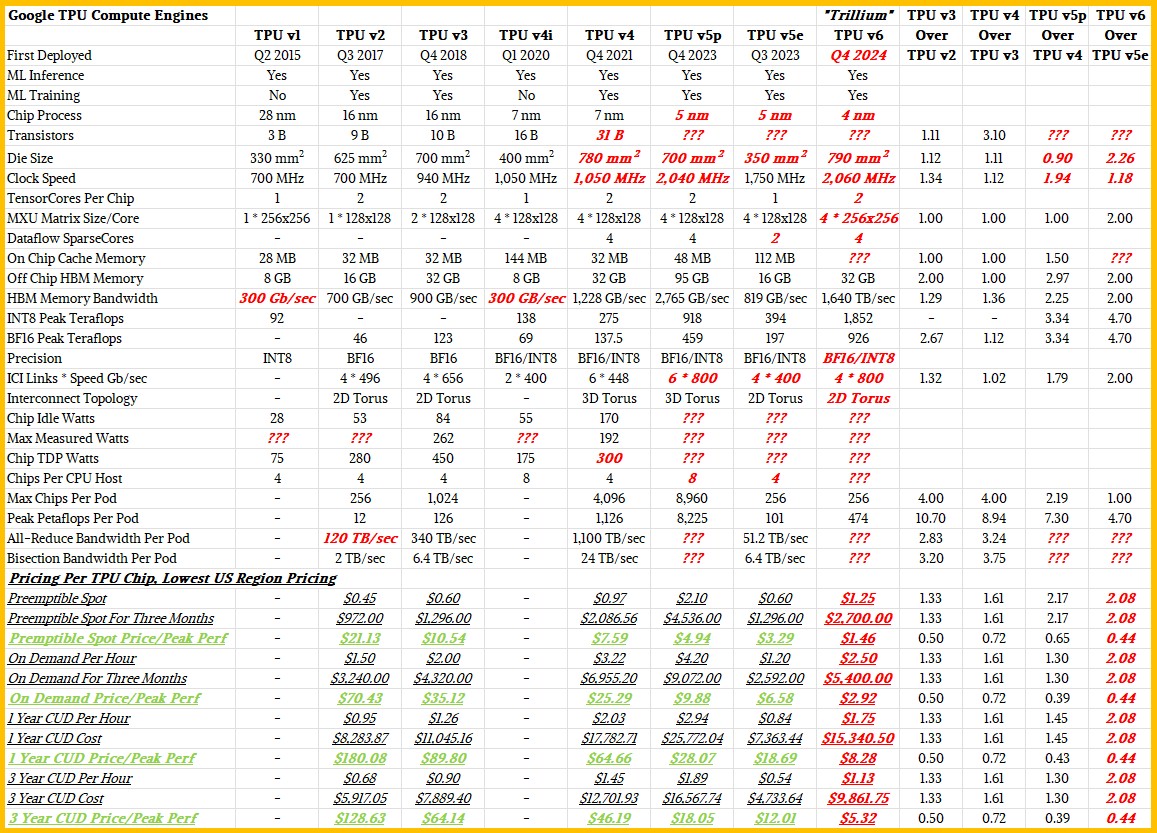
As usual items in bold red italics are estimations by The Next Platform.
Google does not supply feeds and speeds for all TPUs uniformly, and it is all the more curious as to why. The scale of the TPU v4i pods was never disclosed and neither was its pricing. Chip sizes and process nodes are missing on the more recent TPUs and so are some basic thermals such as maximum and idle wattages. Where we could calculate values – such as INT8 and BF16 performance for the Trillium chip – we did, and those figures are shown in black because a calculation is not an estimation.
The feeds and speeds of the TPUs and their host and pod scalability are all interesting, but we also think the trend in price/performance over time is equally important, and we do have data for this.
The first thing we can tell you is that since we did our deep dive on the TPU v4 architecture ion October 2022, Google has actually raised the prices on TPU v2 capacity. And frankly, these devices are now seven years old and offer very poor bang for the buck compared to more recent TPU generations that we are surprised that pricing is not a lot lower for the TPU v2 capacity on Google Cloud.
Our guess is that with the TPU v6, Google is going to actually raise the price of renting one of these devices by a little more than a factor of 2X and that the resulting Trillium instances will still offer more than 2.3X better bang for the buck than the TPU v5e instances on Google cloud and 3.4X better price/performance than the TPU v5p, which is a much heavier device more suitable for AI training than AI inference even though it can do both.
The point is, TPU v6 is so much better that Google can charge more per device and still give customers a much better deal on AI training and inference throughput. And if there is a TPU v6e, as we suspect, the inference cost could be even lower and if there is a TPU v6p the training cost could come down further.
The other interesting thing in the trend in lowering cost for TPU instances over time if Google’s pricing comes out as we think it will for the Trillium instances. For preemptible (spot) instances, the cost per unit of performance at the finest data resolution available on a TPU chip has gone down by a factor of 14.5X between the TPU v2 in 2017 and the TPU v4 this year. On demand pricing will have fallen by 24.2X over, one year reserved instances by 21.7X, and three year reserved instances by 24.2X.
We shall see what comes to pass. As soon as we know more, we will let you know and we will be happy to do competitive analysis with homegrown accelerators and GPUs on the cloud.
